-
딥러닝은 확률론 기반의 기계학습 이론에 바탕을 두고 있으며, 기계학습의 loss function들의 작동 원리는 데이터 공간을 통계적으로 해석하여 유도한다. 확률을 통해 데이터를 모델링 할 수 있다.
- 이산형 확률변수: 확률 변수가 가질 수 있는 모든 경우의 수를 더해서 확률을 모델링
- 연속형 확률변수: 데이터 공간에 정의된 확률변수의 밀도 위에서의 적분을 통해 모델링
주변 확률 분포: 결합확률분포를 하나의 확률변수에 대해 모두 더해주거나 적분해주어 구할 수 있는 다른 확률변수에 대한 분포
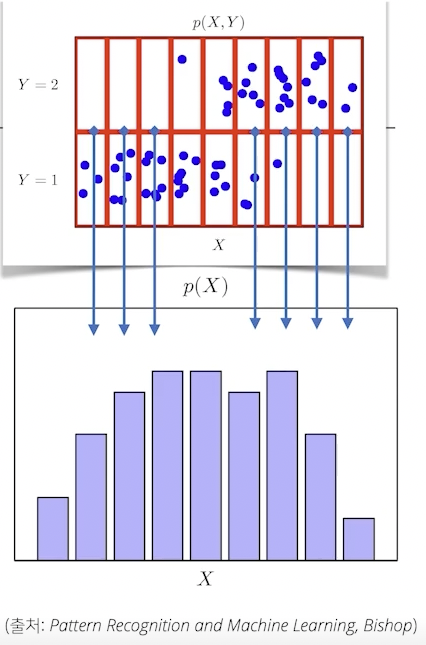
조건부 확률분포: 데이터 공간에서 입력 x와 출력 y 사이의 관계를 모델링

분류 문제에서 softmax 함수는 데이터 x로 부터 추출된 특징패턴과 가중치행렬을 통해 조건부 확률 P(y|x)를 계산.
회귀 문제의 경우 조건부 기대값 E[y|x} 을 추정. 회귀 문제의 경우 주로 연속인 데이터를 다루기 때문에 적분을 이용.

조건부 기대값은 $ E||y-f(x)||_2 $ 을 최소화하는 함수 f(x)와 일치한다.
기계학습의 많은 문제들은 확률분포를 명시적으로 모를 때가 대부분이기 때문에 데이터를 이용하여 기대값을 계산해야한다. 이때 사용되는 방법은 Monte Carlo 샘플링 방식이다. 독립적으로 샘플링 해야함.

몬테카를로 샘플링 몬테카를로 방식으로 적분을 근사할 수 있다.
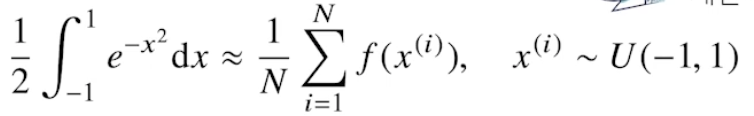
[-1, 1] 구간의 균등분포에서 샘플링을 한 뒤, 샘플링한 x값을 함수에 대입하고, 산술평균을 취해주고 구간의 길이만큼 곱한다.
과제 및 피어세션
과제를 진행하며 pythonic 하게 코드를 작성하는 연습을 했다.
만약 특정 문자(Ex 모음)을 제거한 문자열을 만들고 싶다면 다음과 같이 간단하게 코드를 한줄로 작성할 수 있다.
no_vowel_string = ''.join( x for x in input_string if x not in vowels)리스트를 만들때도 다음과 같이 간단하게 숫자만 포함하는 리스트를 생성할 수 있다.
input_string = [x for x in input_string if x.isnumeric()]
느낀점
pythonic 하게 코드를 작성하는 연습을 더 많이 해야겠다. numpy와도 더 친해질 필요가 있을 것 같다. 통계학, 확률에 대한 공부가 더 필요할 것 같다.
'AI > 1주차' 카테고리의 다른 글
1~4. AI Math (2) 2021.08.06 9. CNN & RNN (0) 2021.08.05 8. 베이즈 통계학 (0) 2021.08.04 7. 통계 기본 (0) 2021.08.04 5. 딥러닝 학습방법 이해하기 (0) 2021.08.03