-
QA with Phrase RetrievalNLP/MRC 2021. 10. 18. 14:46
Limitation of Retriever-Reader approach
- Error Propagation: 5-10개의 문서만 reader에게 전달됨
- Query-Dependent encoding: query에 따라 정답이 되는 answer span에 대한 encoding이 달라짐
Phrase Search

기존의 방식은 question이 들어올 때마다 F라는 function을 다시 계산했어야한다.

Decomposiability Gap: 기존 Question, Passage, Answer가 모두 함께 encoding 되던 것이 G와 H로 나누어지지 않을 수 있다.
→ question과 passage 사이 attention x
Dense Vector vs Sparse Vector
- Dense vector: 통사적, 의미적 정보를 담는데 효과적
- Sparse Vector: 어휘적 정보를 담는데 효과적
Dense + Sparse vector를 합쳐서 임베딩
Dense Representation
- Dense Vector
- Pre-Trained LM (e.g. BERT)를 이용
- Start, end vector를 재사용
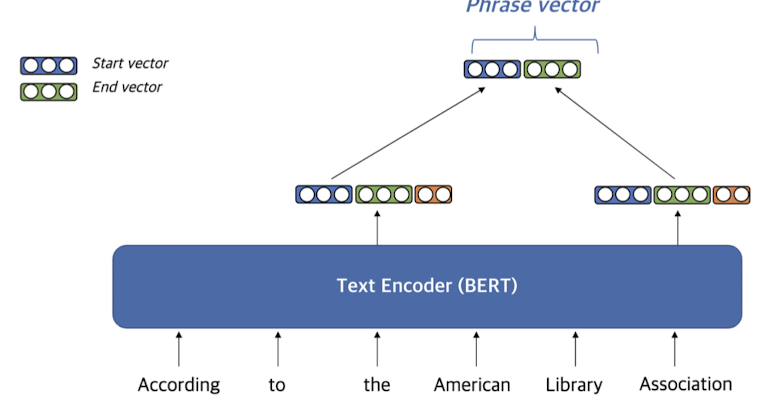
- Coherency Vector
- phrase가 한 단위의 문장 구성 요소에 해당하는지를 나타냄
- 구(句)를 형성하지 않는 phrase를 걸러내기 위해 사용함
- Start vector와 end vector를 이용하여 계산

- Question Embedding

Sparse Representation

https://arxiv.org/abs/1911.02896
Contextualized Sparse Representations for Real-Time Open-Domain Question Answering
Open-domain question answering can be formulated as a phrase retrieval problem, in which we can expect huge scalability and speed benefit but often suffer from low accuracy due to the limitation of existing phrase representation models. In this paper, we a
arxiv.org
https://arxiv.org/abs/1906.05807
Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index
Existing open-domain question answering (QA) models are not suitable for real-time usage because they need to process several long documents on-demand for every input query. In this paper, we introduce the query-agnostic indexable representation of documen
arxiv.org
'NLP > MRC' 카테고리의 다른 글
Closed book QA with T5 (0) 2021.10.18 Reducing Bias (0) 2021.10.18 Open Domain Question Answering (0) 2021.10.13 Passage Retrieval - Scaling Up (0) 2021.10.13 Dense Embedding (0) 2021.10.13