-
TextRank를 이용한 추출적 요약 - 1NLP 2021. 1. 12. 16:07
TextRank는 PageRank 기반의 알고리즘으로, 키워드 추출과 추출적 요약에 주로 사용된다. 따라서 TextRank를 이해하기 위해서는 PageRank에 대한 이해가 선행되어야 한다.
PageRank란?
구글에서 개발한 알고리즘으로 초기 구글의 검색 엔진의 랭킹 알고리즘으로 이용되었다. PageRank에서는 모든 웹 페이지들을 webpage 가 node인 큰 directed graph 형태로 본다. 만약 A라는 페이지에 B라는 페이지로 향하는 링크가 있다면, A에서 B로 향하는 directed edge가 있다고 볼 수 있을 것이다. PageRank 알고리즘에서는 페이지들의 연결 상태를 나타내는 그래프를 형성한 뒤, 각 webpage에 대한 weight를 다음과 같은 공식을 통해 계산한다.

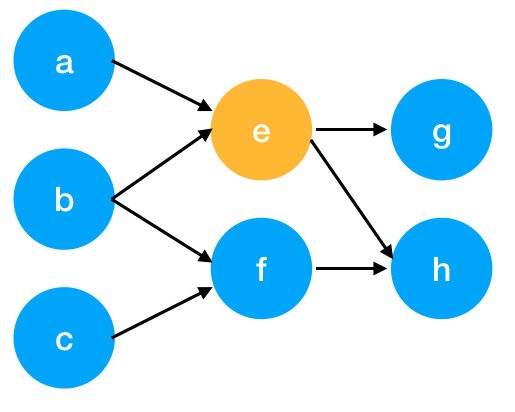
아래와 같은 그래프에서 webpage e에 대해 위 공식을 적용시켜보자.
공식에서 시그마 부분을 간단하게 나타내면 다음과 같이 나타낼 수 있다.
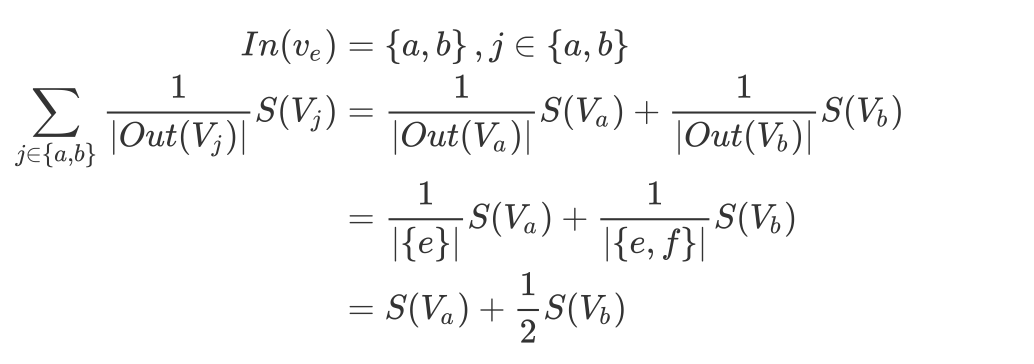
이를 공식에 대입하면 아래와 같은 식이 나온다.
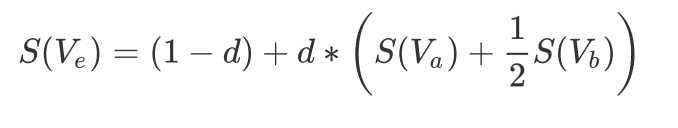
따라서 webpage e의 weight은 inbound page들의 weight에 dependent함을 볼 수 있다.

그래프의 연결 상태를 normalize 하여 행렬로 나타내고, 각 node들에 초기 weight로 1을 부여하여 내적을 통해 e의 새로운 weight를 계산하면 위 그림과 같다.
import numpy as np g = [[0, 0, 0, 0], [0, 0, 0, 0], [1, 0.5, 0, 0], [0, 0.5, 0, 0]] g = np.array(g) pr = np.array([1, 1, 1, 1]) # a, b, e, f의 초기값 1 d = 0.85 for iter in range(10): pr = 0.15 + 0.85 * np.dot(g, pr) print(iter) print(pr)damping factor까지 추가하여 각 node들의 weight을 계산하는 파이썬 코드를 돌려보면 아래와 같은 weight 값이 나온다.

참고자료
https://towardsdatascience.com/textrank-for-keyword-extraction-by-python-c0bae21bcec0
'NLP' 카테고리의 다른 글
TextRank를 이용한 추출적 요약 - 2 (1) 2021.01.13