NLP/2주차
NLP 모델 정리
jnnwnn
2021. 9. 16. 16:20
GPT-2
- 큰 트랜스포머 LM
- Trained on 40GB text (큰 데이터) - Reddit의 데이터 이용, 위키피디아는 이용 x
- Downstream task를 zero-shot setting에서 가능하게 함
- QA - CoQA dataset에서 55 F1 score
- Summarization - CNN, Daily Mail dataset
- 번역
- BPE 사용
- GPT-1 과 다른점
- Layer Norm을 각각의 하위 Block의 Input으로 이동
- 마지막 self-attention 이후에 Normalization Layer 추가
- 모델 깊이에 따른 Residual Path의 누적에 관한 부분의 초기화 방법 변경 ($ 1 / \sqrt{n} $, n은 number of residual layer)
- Context size 변경 512 -> 1,024
- 서로 다른 매개변수의 4개의 모델을 사용
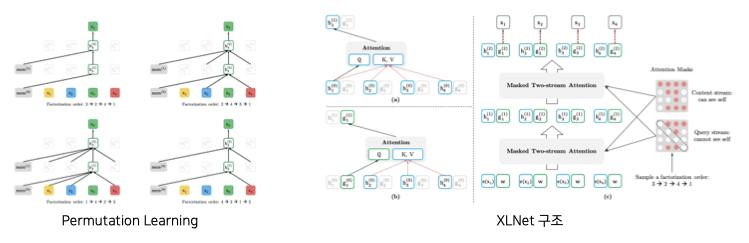
GPT로 대표되는 Auto Regressive (AR) 모델과 BERT로 대표되는 Auto Encoder (AE) 모델의 장점을 결합.
- AR 모델은 단방향성 단점
- AE 모델은 mask token 간 independence를 가정하고, fine tune과 pre-train 사이에 괴리가 존재한다는 단점
XLNet은 입력의 permutation들을 이용하여 maximum likelihood를 계산
RoBERTa
BERT의 성능을 hyper-parameter tuning과 학습사이즈 조절을 통해 개선
- 더 많은 데이터와 더 큰 batch로 학습
- NSP 제거
- 더 긴 sequence로 학습
- masking을 dynamic하게 변경 (기존의 BERT는 매 학습 단계에서 동일한 mask를 본다)
BART
Transformer Encoder-Decoder 통합 LM
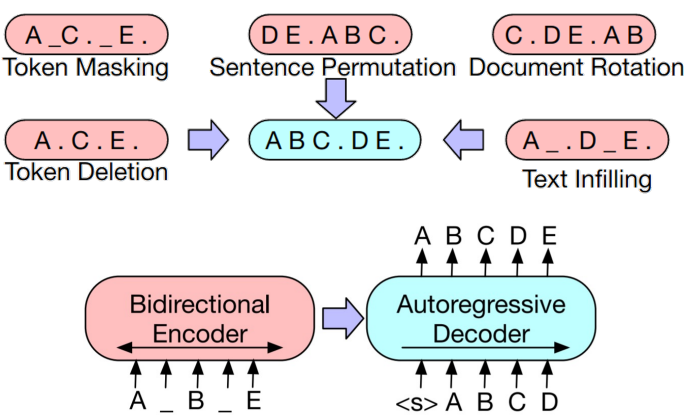
T-5
Transformer Encoder-Decoder 통합 LM (SOTA)

GPT-3
- 모델의 크기를 키움
- 모델의 크기를 키울수록, few-shot, one-shot, zero-shot 성능이 올라감

기존의 Pre-trained LM은 모델의 크기가 커서 문제점들이 존재
- Memory Limitation
- Training Speed
해결 방안
- Factorized Embedding Parameterization
- BERT에선 Embedding Size와 Hidden Size가 같아야 한다. 이는 vocabulary size가 커질수록 문제를 일으킨다. V개의 단어를 H 차원으로 변환하기 위해서는 O(V x H) 차원의 행렬이 필요. ALBERT는 이 사이에 E 라는 크기를 갖는 Embedding을 추가하여 O(V x E + E x H)로 변환한다. E가 H에 비해 충분히 작으면, 메모리를 효과적으로 절약할 수 있다.

- Cross-layer Parameter Sharing
- layer간 가중치 공유
- Sentence Order Prediction (SOP)
- NSP가 너무 쉬운 문제
- Negative Pair의 경우 연속된 문장을 뽑고, 문장의 순서를 바꾸어 배치
ELECTRA (Efficiently Learning an Encoder that Clasifies Token Replacements Accurately)
- Discriminator가 단어들이 generator에서 생성된 것인지 아닌지 판별
- 모든 단어에 대해 학습을 하기 때문에 mask된 부분에 대해서만 loss를 계산하는 BERT 보다 학습이 빠름

Light-weight Models
- DistillBERT
- Teacher Model & Student Model → param이 적은 student model이 teacher model의 distribution을 최대한 유사하게 하도록 하는 triple loss 사용
- TinyBERT
- 중간 결과물까지 student network이 담도록
Knowledge Graph into Language Model
- ERNIE (Enhanced Language Representation with Informative Entities)
- KagNET (Knowledge-Aware Graph Networks for Commonsense Reasoning)
대화를 위한 LM
- Meena
- 인코더 블럭 하나와 다수의 디코더 블럭으로 구성
- SSA (Sensibleness and Specificity Average)라는 챗봇을 위한 새로운 Metric 제시
Controllable LM
- Plug and Play LM (PPLM)
- 확률 기반 모델의 윤리성을 해결 가능 → 특정 카테고리에 대한 감정을 컨트롤해서 생성 가능
- 확률 분포를 사용하는 것이기 때문에 중첩도 가능 (기쁨 + 놀람)
- 원하는 단어들의 등장 확률이 최대가 되도록 이전 상태의 벡터를 수정
- 수정된 벡터를 통해 다음 단어 예측

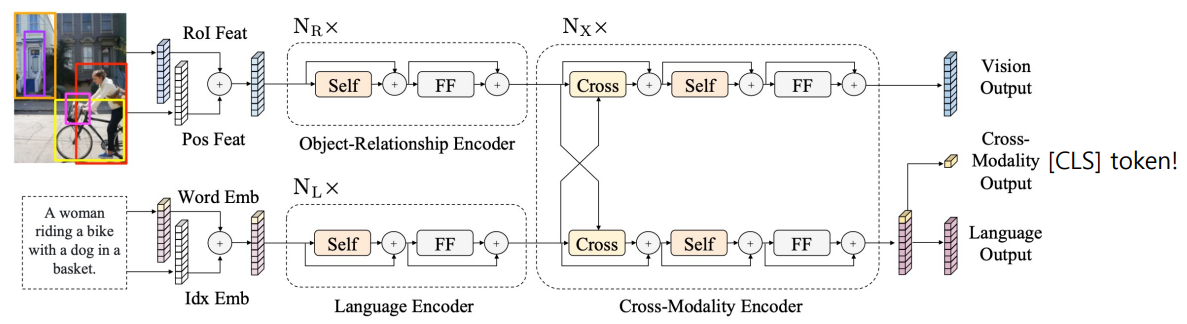
Multimodal
- LXMERT → 이미지와 자연어를 동시에 학습