-
Passage RetrievalNLP/MRC 2021. 10. 13. 11:57
Passage Retrieval
질문에 맞는 문서를 찾는 것.
Open-domain Question Answering
대규모의 문서 중에서 질문에 대한 답을 찾기
- Passage Retrieval + MRC의 2 stage

Passage Embedding Space
- Passage Embedding의 벡터 공간
- 벡터화된 passage를 이용하여 passage 간 유사도 등을 알고리즘으로 계산할 수 있다.
Sparse Embedding
- BoW → n-gram

- Term Value를 결정하는 방법
- 특징
- Dimension of embedding vector = number of terms (등장하는 단어가 많을 수록 커짐, n이 커질수록 증가)
- Term overlap을 잡아낼 때 유용
- 의미가 비슷하지만 다른 단어를 잡아내지 못한다.
TF-IDF
- TF: 단어의 등장 빈도
- Raw count / 전체 단어 수
- IDF: 단어가 제공하는 정보의 양
- $ IDF(t) = log\frac{N}{DF(t)} $
- N: 총 document 개수
- DF(t): term t 가 등장한 document의 개수
BM25
TF-IDF의 개념을 바탕으로, 문서의 길이까지 고려하여 점수를 매김
- TF 값에 한계를 지정해두어 일정한 범위를 유지하도록 함
- 평균적인 문서의 길이보다 더 작은 문서에서 단어가 매칭된 경우 그 문서에 대해 가중치를 부여
- 실제 검색엔진, 추천 시스템 등에서 아직까지도 많이 사용되는 알고리즘
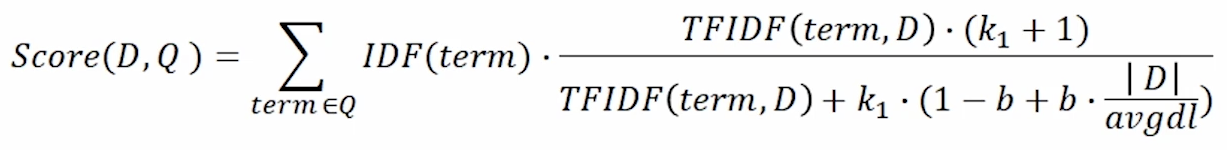
https://github.com/castorini/pyserini/blob/master/docs/experiments-msmarco-doc.md
GitHub - castorini/pyserini: Pyserini is a Python toolkit for reproducible information retrieval research with sparse and dense
Pyserini is a Python toolkit for reproducible information retrieval research with sparse and dense representations. - GitHub - castorini/pyserini: Pyserini is a Python toolkit for reproducible info...
github.com
'NLP > MRC' 카테고리의 다른 글
Passage Retrieval - Scaling Up (0) 2021.10.13 Dense Embedding (0) 2021.10.13 Generation based MRC (0) 2021.10.13 Extraction-Based MRC (0) 2021.10.12 Introduction to MRC (0) 2021.10.12